
We're very excited to announce the release of Google BigQuery support for storage and modeling with Objectiv.
Next to the ability to validate & store Objectiv data in BigQuery, we’ve enabled working with the open model hub and modeling library Bach (an SQL abstraction layer with pandas-like syntax) directly on your full BQ dataset.
This is an important step in our mission to enable data models to run across data stores, so data teams can take and run what someone else made, or quickly build their own with pre-built models and operations. All current models and operations now work with both PostgreSQL and Google BigQuery, with Amazon Athena next, and more data stores coming.
An example: A retention matrix directly on BigQuery
We’ll use the retention matrix model from the open model hub as an example. To run this model directly on the full dataset in BigQuery, simply call modelhub’s retention_matrix operation, and choose the desired timeframe (daily, weekly, monthly, or yearly):
retention_matrix = modelhub.aggregate.retention_matrix(
df,
time_period='monthly',
percentage=True,
display=True)
retention_matrix.head()
This operation is then translated to SQL by the underlying Bach modeling library, and executed directly in BigQuery:
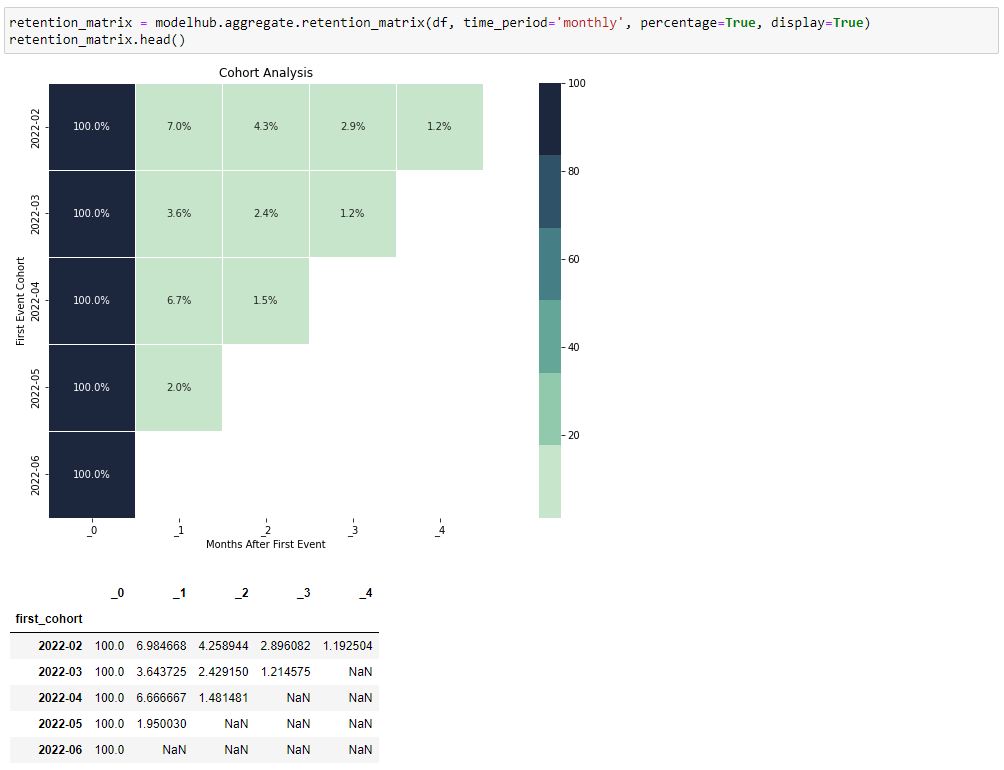
Once the query completes, the result is returned and shown in a heatmap in your notebook (or as a
DataFrame, if you use parameter display=False):
Optionally, if you want to reduce data usage or query complexity, you can work with a sample, or temporarily materialize intermediate results.
A Machine Learning example: Logistic regression directly on BigQuery
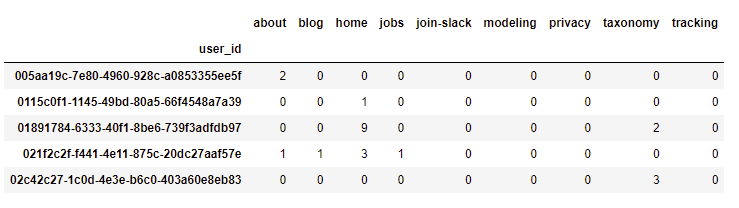
Let’s take a machine learning model from the open model hub: LogisticRegression. As a simple example, we’ll predict if users on our own website will reach the modeling section of our docs, by looking at interactions that they have with all the main sections of our website. We’ll use the simple dataframe below, which counts the number of clicks per user in each section of our website, using the root location:
See this example notebook for the intermediate steps of sampling the data,
initializing the model, and fitting it. Note that for fitting the model, data is extracted from BigQuery
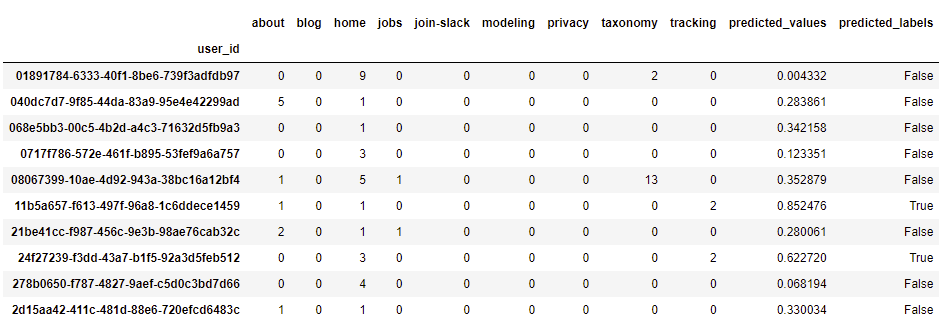
under the hood. We can then create columns for the predicted values and labels in the sampled data set, and
show the predictions (True if probability is >0.5):
features_set_sample['predicted_values'] = lr.predict_proba(X)
features_set_sample['predicted_labels'] = lr.predict(X)
# show the sampled data set, including predictions
features_set_sample.head(10)
Now that we have the model results, the data can easily be unsampled to work with the full data set in BigQuery, and its SQL exported to run in production:
features_set_full = features_set_sample.get_unsampled()
display_sql_as_markdown(features_set_full)
How it works
Objectiv’s Collector can receive & validate data captured by the Tracker SDKs, and store it in
your data store of choice. To store data in BigQuery requires a Snowplow pipeline setup
that connects to Google Cloud Platform. The Collector can then be configured to hook directly into
Snowplow’s Enrichment step.
How to get it
1) Set up BigQuery with Objectiv via the Snowplow pipeline
Read how to configure Google BigQuery with Objectiv in the documentation.
2) Install/update modelhub/Bach packages
Install from PyPI:
pip install objectiv-modelhub
Or upgrade if you’ve already installed it:
pip install --upgrade objectiv-modelhub
3) Connect from your notebook
Finally, connect directly to the data in BigQuery from your notebook:
df = modelhub.get_objectiv_dataframe(
db_url='bigquery://your_project/snowplow',
start_date='2022-06-01',
end_date='2022-06-30',
table_name='events',
bq_credentials_path=BQ_CREDENTIALS_PATH)
This creates an Objectiv DataFrame that points to the data in BQ, and all operations are done directly on it.
Summarizing
With this release we’re taking an important step in our mission to enable data models to run across data stores. We’ve added support to validate & store Objectiv data in Google BigQuery, and to work with the open model hub and modeling library Bach directly on your full BQ dataset. It works by hooking the Objectiv Collector into a Snowplow pipeline setup, which connects to the Google Cloud Platform.
All current models and operations now work with both PostgreSQL and Google BigQuery, with Amazon Athena next, and more data stores coming.
Tell us what to support next on Slack!
Office Hours
If you have any questions about this release or anything else, or if you just want to say 'Hi!' to team Objectiv, we have Office Hours every Thursday at 4pm CET, 10am EST that you can freely dial in to. If you're in a timezone that doesn’t fit well, just ping us on Slack and we'll send over an invite for a better moment.