Powerful product analytics for data teams
Objectiv is an open-source data collection & modeling platform that enables data teams
to run product analytics from their notebooks with full control over data and models.
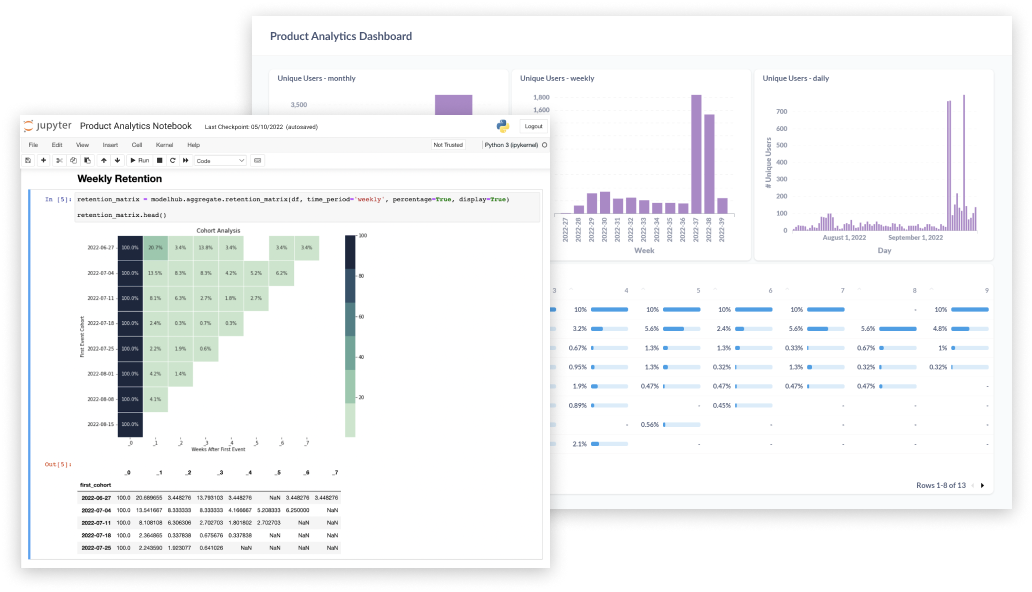
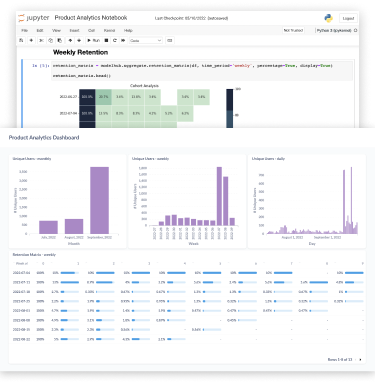
Control your product analytics in code
Take product analytics into your own hands with full access to data and models from your Python notebook.
Model with zero grunt work
Work directly on super-structured raw data, with pre-built models designed for product analytics.
First party data & built for integration
Objectiv connects to your own data store of choice and plays nice with most tools in the modern data stack.
Set up validated, error-free tracking
Get helpful tooling to test, validate and debug your tracking setup at multiple stages. No surprises downstream.
Join the frontrunners in our growing product analytics modeling community








How does Objectiv work?

instrument Objectiv's tracker into your app/site
with the help of a very supportive tracking SDK

collect super-structured user behavior data
and send it directly into your data store of choice

analyze the data from your notebook with
pre-built models, or build your own

output your model to SQL with one command and
use it in BI tools, products, dbt, pipelines, etc...

Blends right into your stack
Objectiv runs in your favourite notebook and integrates with Snowplow.
Any SQL-based BI tool
e.g. Metabase, Looker, SiSense
Any Python-based notebook
e.g. Jupyter, Hex, Deepnote, Colab
Any SQL-based platform/pipeline
e.g. dbt, Airflow, Dagster, Prefect, Transform
Any SQL data store
e.g. BigQuery, Athena, RedShift, Snowflake, Databricks, ClickHouse
Snowplow
Host it yourself, or let us do the heavy lifting
Whichever path you choose, we've made things easy for you.
SELF-HOSTED

Objectiv Up
Self-host Objectiv in under five minutes. 100% free, pre-configured and ready to use for production.
Learn MoreFULLY MANAGED

Objectiv Cloud
A fully managed back-end. Run Objectiv at massive scale without worrying about the Ops part.
Learn MoreObjectiv is fully open-source. You can also manually build & run your own custom Objectiv platform, or integrate it into an existing Snowplow pipeline.
Get started with Objectiv
View Example Notebooks
Check out what you can do with Objectiv
Run Objectiv Up
Try out Objectiv on your local machine
Instrument the Tracker
Start collecting user behavior data
You can find our official repo on GitHub and join our Slack channel if you need any help.