
The modern data stack is on the rise. Many companies use raw data from their SaaS analytics tools as input for their data warehouse, but this introduces problems downstream. Are there better ways?
Popularization of the all-in-one SaaS analytics tool
When Google Analytics launched nearly 20 years ago, it took the market by storm. Its success created the mold for SaaS-based analytics offerings that included everything in one box: data collection, storage, analysis & visualization.
Ease-of-use and low barrier of entry were two of its main drivers. Instrumentation typically required little in terms of engineering resources and the included analyses, although somewhat limited, were ready to be used by a broad audience.
Urchin Analytics, to become Google Analytics after acquisition.
The big shift towards data warehousing
While SaaS analytics tools are still very popular and widely used, their wild growth has left the data analysis landscape highly fragmented. Most companies have numerous tools collecting data, and each of them have a different way of analyzing & consuming it. As a result, it’s very hard to get a holistic view of what all that combined data is telling you.
We’re seeing a major shift where companies export data from their SaaS analytics tools to use as input for their data warehouse. Not only to create a single source of truth for all data consumers, but also to unlock the potential of raw data. By combining full raw data sets, you can go way beyond the scope of your SaaS analytics tools. You’re technically only limited by the quality and completeness of the data.
The rise of the modern data stack
The big shift towards data warehousing is represented by the upsurge of companies that operate in this space and how fast they’re growing. Over 10.000 companies now use Snowplow to process events at scale and send them straight into the DWH. dbt now has over 9.000 weekly active data transformation projects. 13.000+ sites and apps are running RudderStack to pull data from SaaS tools and send it into data warehouses. The list goes on.
dbt Cloud in action
... but SaaS analytics tools aren’t great input for your DWH
Most data warehouses are fed with data that’s collected by all-in-one-box SaaS analytics tools. While historically explainable, this often causes problems downstream.
The data they collect is not designed for advanced modeling
There is a big difference between what data teams want their raw data to look like and what it actually looks like when it comes from SaaS analytics tools. The data sets they collect were never designed for advanced modeling on the raw data. It is often incomplete or overcomplete, unstructured and ambiguous. Significant grunt work is typically required before it can be used for modeling.
Data duplication frustrates adoption of a single source of truth
By extracting data from SaaS tools and loading it into a data warehouse, you’re effectively duplicating a source.
SaaS analytics tools all offer their own way to consume the collected data, and chances are many of your company’s data consumers still rely on the dashboards of these tools to inform their daily decisions. Either out of habit, or simply because it offers an easy & fast way to get data.
In practice, this often leads to discussions about why numbers of different teams don’t seem to be adding up, as the data team and data consumers both use different versions of the same source of data as input.
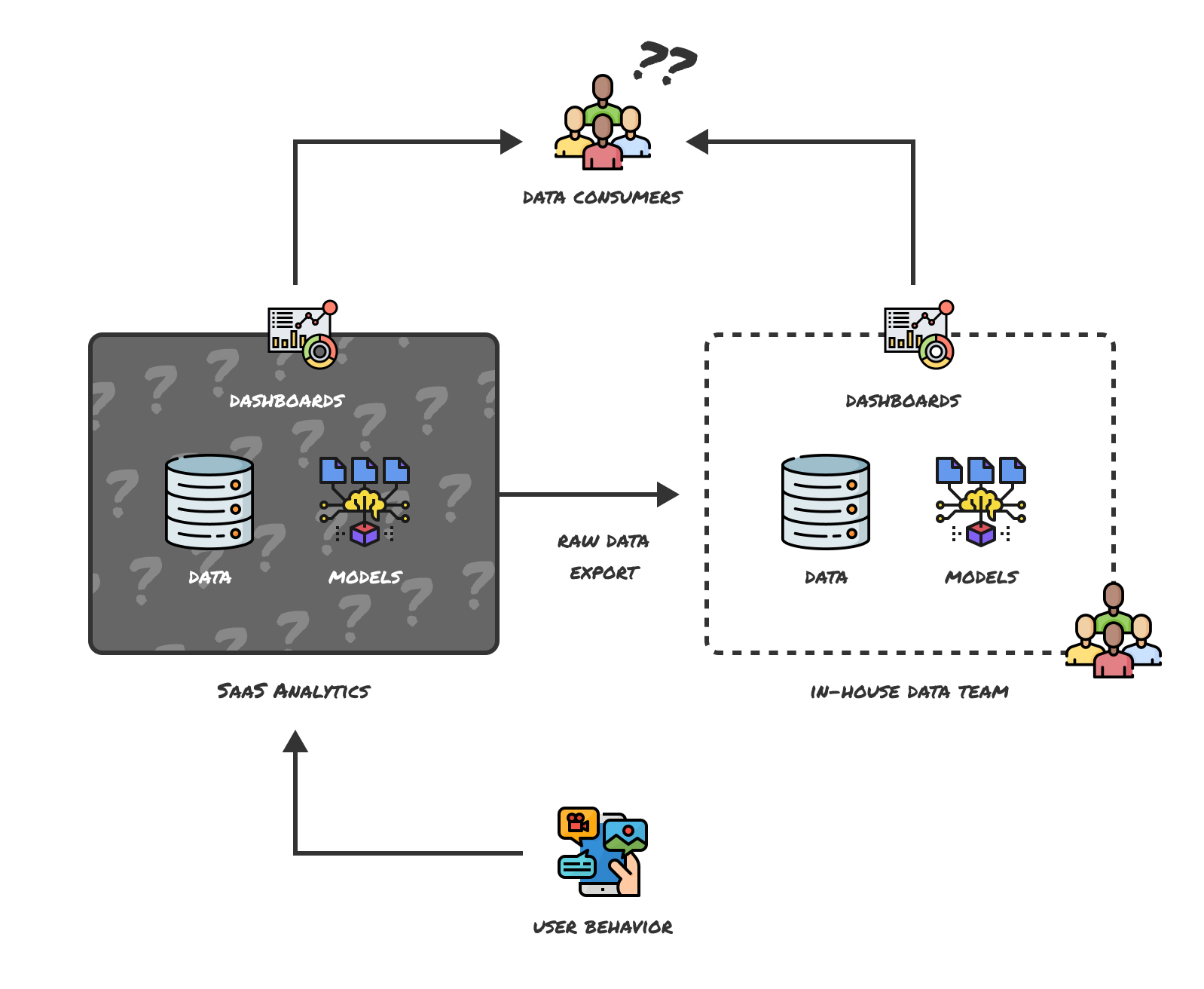
They operate as black boxes
SaaS analytics tools typically don’t disclose the actual models behind an analysis. As a result, rebuilding an analysis to work with the data set in your data warehouse requires significant reverse engineering effort, and troubleshooting & debugging can be painful when anything is off.
Unbundling SaaS analytics tools
The way data is used has evolved, and the all-in-one-box model that SaaS analytics tools use no longer fits. In order to effectively combine and analyze data from multiple sources and truly serve all data consumers from a single source of truth, we need to unbundle the black box and separate data collection, storage, modeling and visualization.
Moving all data consumption downstream
By separating data collection, all collected data can be sent straight into the data warehouse without stopovers. This eliminates source duplication and moves data consumption downstream. It enables all analysis & visualization to occur on a single source of truth: the data warehouse.
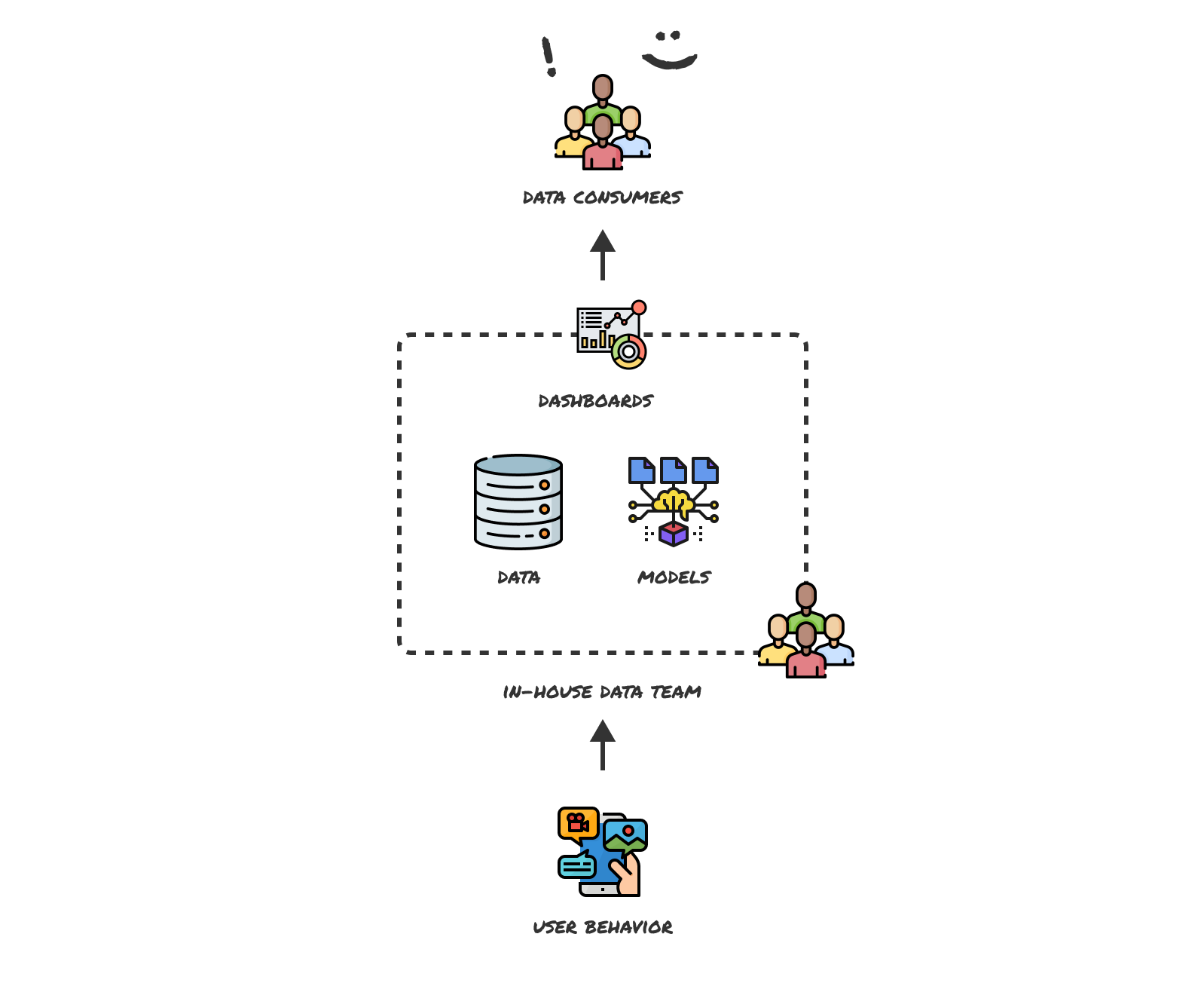
Shifting from vendor-locked tools to raw data and code
Unbundling the black boxes also provides a big opportunity for the adoption of open standards. Shifting from vendor-locked tools to raw data and code enables data teams to adopt generic ways of structuring data to share and reuse each others’ tools, models and analyses.
We think the future of analytics is open and data warehouse-native, and there are clear signals we’re already on the way. It’s time to enable meaningful collaboration and to unbundle SaaS analytics.