
The tracking plan. Every company that’s serious about analytics has one, but they are notoriously difficult to properly set up & execute. What if you didn’t need one?
The history of the tracking plan
In the early days, you would spin up Google Analytics, analyze your pageviews and sip your coffee. Everything was straightforward and you would have a pretty clear idea of what you were looking at.
The introduction of event-based tracking opened up a whole new level of insights for companies to tap into. No longer would you be restricted to pageviews, but you could now analyze user behavior in great detail by capturing each interaction in an event.
With this great power came great responsibility. Without proper naming conventions, event-based datasets quickly become an entangled mess that’s impossible to analyze. In order to prevent this, teams started capturing the structure and names of their events in a tracking plan. Sometimes with purpose-built tools, but most of the time in an elaborate excel sheet. These are then handed over to the engineer responsible for setting up the tracker.
Mixpanel's tracking plan template
The goal of the tracking plan is to ensure data sets contain the right information for effective analysis. In practice however, the resulting data sets are often far from perfect.
Why most tracking plans fail
1. You only really know what data you need when you start analyzing
Setting up a tracking plan requires forecasting what kind of analysis and modeling your team would like to do down the road. Even for an experienced team, this is incredibly hard. Misjudgement on these requirements means you will lack vital data at analysis time, and the historical gap is often hard, if not impossible to fix.
2. The instrumenter is often in the dark on the intent of the plan
Engineers may know every nitty gritty detail of the app that’s being tracked, but don’t always have the full picture when it comes to what’s required from a data perspective. As such, tracking plans are prone to misinterpretation, which leads to errors in the instrumentation as a result.
3. Tracking requirements change all the time
In an ideal world, a tracking plan wouldn’t change once it’s set up. In reality, changes to the product or requirements of the data teams means that tracking plans are evolving continuously. This creates a constant loop of work. Not only the engineers that have to do the actual instrumentation, but also everyone else involved in using the data.
4. N = 1
Every single company creates and maintains their own tracking plans, yet the goals of their data teams are all surprisingly similar. We’ve had the privilege to look inside the kitchens of over 50 data teams from different companies. They are all looking for the same answers. What’s driving conversion? How do I get engagement up? How do we personalize experiences? Can we prevent churn?
Why does everyone create their own tracking plan when they all want to know the exact same things?
Using collective knowledge to replace the tracking plan
Early 2021, we went to the drawing board and asked ourselves:
- What are the common types of analyses that we saw from the 50+ data teams we've worked with?
- What kind of data would you need to perform them all from one dataset?
- How would you structure it to enable data teams to use it effectively?
- How do we provide the engineer the context & help required to set up error free instrumentation?
After countless sessions, iterations and field tests, we came to what we now call the open analytics taxonomy.
The open analytics taxonomy
The open analytics taxonomy is a generic way to track analytics events, built on the collective experience of data teams from a wide range of companies. It describes classes for common user interactions and their contexts.
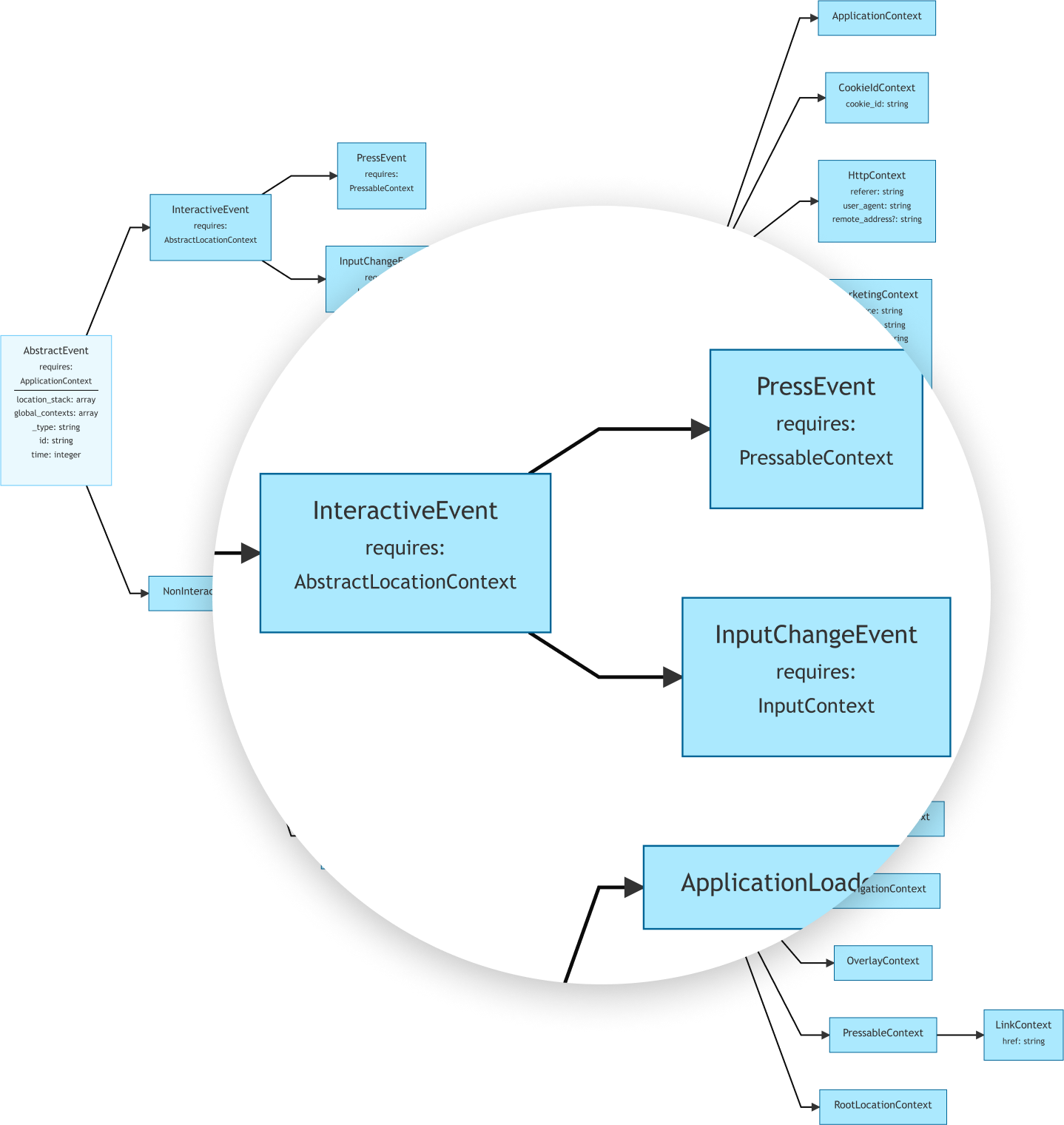
The open analytics taxonomy
It’s designed to capture rich user behaviour data that covers a broad spectrum of product analytics use cases. Objectiv’s tracking SDK uses it to validate all collected data. This ensures it is ready for modeling without any cleaning or transformation.
As a result of high data consistency, all models that embrace the open analytics taxonomy can be shared and reused between teams, projects & platforms.
Can I use it to replace my tracking plan?
Yes, you can:
- Check out the full documentation of the open analytics taxonomy.
- Get the Objectiv tracking SDK to instrument your website, web-app or app
- Use the SDK's validation to check and debug your instrumentation
- Explore the schema that is automatically generated and used for validation of all collected data.
The same schema is also used by the Open Model Hub, which includes pre-built models for a wide range of common analytics use cases.
The Open Analytics Taxonomy is open-source. We’ve started with a taxonomy for product analytics as it’s the bedrock of the user journey, and are currently extending the taxonomy to cover marketing use cases as well. More will follow.
Have questions or want to stay in the loop?