
In early 2021, our team of long-time data geeks started on the development of an open analytics taxonomy. The goal: to come up with a generic way to structure analytics data, so models built on one data set can be deployed and run on another.
A brief history
We used to spend our days building models and running in-depth user behavior analyses on raw datasets for enterprise clients. Those datasets were mostly collected with popular analytics tools like Google Analytics, Mixpanel and Adobe Analytics.
Having done this for 50+ clients, one thing in particular started to stand out: most clients had very similar analytics goals, but their data sets all looked different.
They all wanted to prevent churn, increase engagement or conversion, personalize user experiences, and predict behavior, but every in-house team had made up their own event types, naming conventions and ways to structure data. As a result, nothing could be reused. Pipelines and models all needed to be built from scratch, and significant time was spent to get data into a clean, model-ready state.
At this point in time, we became intrigued with the idea of developing an open analytics taxonomy. If goals are so similar, isn’t there a generic way we can structure analytics data so that all these common analytics use cases are covered? And what would that mean for more specific needs? And, if possible at all, what would that look like?
Fast forward to today. After spending countless hours of drafting ideas on whiteboards, gathering feedback from fellow data scientists and engineers and running experiments with real-life use cases, we’ve come to the point that we’re confident enough to start involving a broader audience.
Allow me to show you what we think it could look like, and explain some of the design choices that were made.
The anatomy of the open analytics taxonomy
The open analytics taxonomy is a generic classification of common event types and the contexts in which they can happen. It's designed to provide a universal structure for analytics data, so models built on one data set can be deployed and run on another.

Bird's-eye view of the open analytics taxonomy
Each event and context type has its own properties and requirements. They're used to validate & debug the collected data, so the resulting data set is ready for modeling without cleaning or transformations.
See the video below for a walkthrough:
Events
Let’s take a closer look at one of the event classes, the PressEvent:
The PressEvent is used to describe when a user clicks or taps (device agnostic) an element in a UI. It is a child of the InteractiveEvent class, the parent of all interactive events.
Events are separated into two subclasses: Interactive events and non-interactive events. The first type gets triggered by a user, the second type typically gets triggered by the application. An example of a NonInteractiveEvent is the MediaStartEvent, which is triggered when audio or video starts playing:
Contexts
You may have noticed that Events require Contexts. These contexts provide additional information to help you pinpoint from where and in which situation an event happened.
Like events, contexts are divided into two subclasses: global contexts and location contexts.
Global contexts contain general information. Examples include user session information, app information or details of a marketing campaign an event is related to.
The MarketingContext, used to capture marketing campaign details
Secondly, location contexts contain information about where an event happened in the UI. For example, the MediaStartEvent mentioned earlier required a MediaPlayerContext to pinpoint from where the event originated. In this case, a media player to be specific, because of its event class.
Use cases & design choices
Let’s take a look at how it can be used and why we made certain design choices.
Data validation
Having strictly defined classes for event and context types means you can validate data at a very early stage. For example, if a MediaStartEvent lacks a MediaPlayerContext, you can throw an error and choose not to store it (or better: store it somewhere else). This will allow you to prevent collection of incomplete or faulty data, saving you a lot of time on prepwork for the analysis stage.
Instrumentation validation
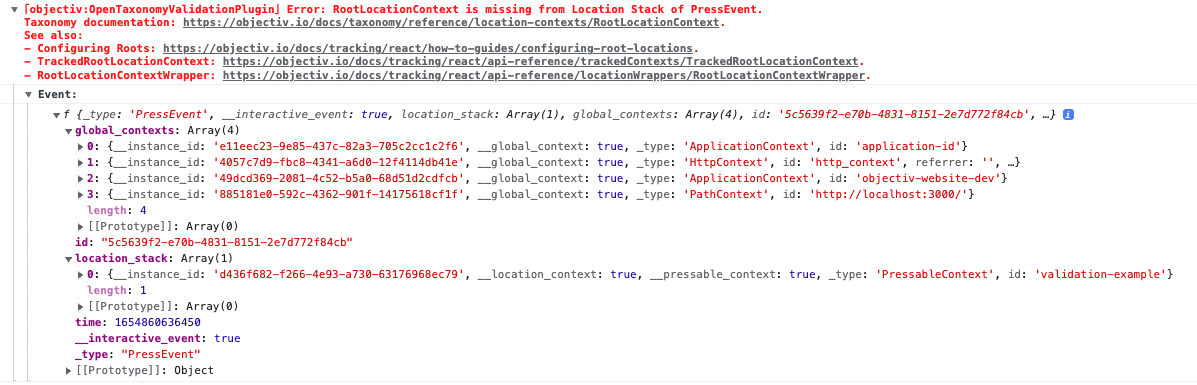
The same principle applies when a front-end developer is instrumenting a tracker to collect data. You can validate the tracking instrumentation against the open taxonomy to ensure it is set up to capture events as intended, and throw errors when conditions aren’t met.
For instance, our own tracking SDK does this by throwing errors at runtime in the browser console, and points you to the documentation to show you how to fix it:
We also use it to provide inline documentation & linting for validation issues in your IDE through TypeScript definitions:

See the video below for a walkthrough:
Feature selection
At the analysis stage, having hierarchy and strict typing in your data is very useful for feature selection. Sub- and superclasses enable you to quickly select events of the type and level you require without manually mapping them first.
Want all interactive events? You can do that with one command in your notebook:
interactive_events = df[df.stack_event_types.json.array_contains('InteractiveEvent')]
Getting only the PressEvents is even simpler:
press_events = df[(df.event_type=='PressEvent')]
This is especially powerful in combination with location contexts. Let me demonstrate how we use them to enable fast feature selection based on the hierarchy of your UI.
We ask the instrumenting engineer to enrich the tracking instrumentation by tagging logical sections of the UI with location contexts. Our tracker then generates a location stack for each event. It captures the exact location where an event was triggered in a hierarchical stack of location contexts.
[
{
"_type": "RootLocationContext",
"id": "modeling"
},
{
"_type": "NavigationContext",
"id": "docs-sidebar"
},
{
"_type": "ExpandableContext",
"id": "open-model-hub"
},
{
"_type": "ExpandableContext",
"id": "models"
},
{
"_type": "ExpandableContext",
"id": "helper-functions"
},
{
"_type": "LinkContext",
"id": "is_new_user",
"href": "/docs/modeling/open-model-hub/models/helper-functions/is_new_user/"
}
]
An example of an Event’s location stack in the modeling section of our docs
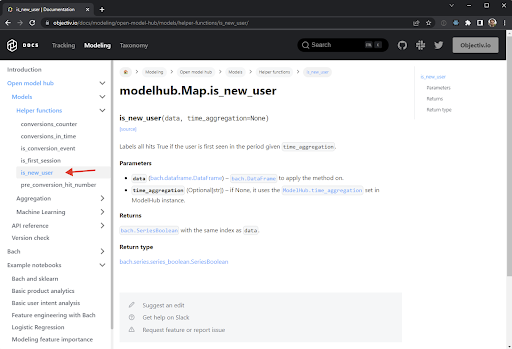
The event above was captured when the user clicked the is_new_user link in the sidebar
As your dataset now carries the logical structure of your product, you can use it to slice events on a very granular level.
For example, you can easily select all events with a NavigationContext:
location_stack.json[{ "_type": "NavigationContext"}:]
Or to be more specific, those that occurred on the docs sidebar:
location_stack.json[{ "id": "docs-sidebar", "_type": "NavigationContext"}:]
...and so on.
The big one: re-use models & tools
For us, this is what started it all. Having a strict, common way to structure analytics data would mean all data sets become consistent and generic, and as a result, models built on one data set can be deployed and run on another.
That user segmentation model you've developed for your Android app? You can share that with the team responsible for the iOS app or web app, and they can deploy and run it without making changes.
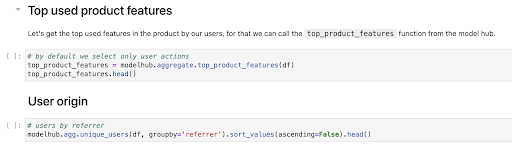
An excerpt from one of our example notebooks. They can be run on any dataset that embraces the open analytics taxonomy.
But we think it’s bigger than that. Every day, someone at another company is solving the exact same problem in a slightly different way. We would like for that to end, and to enable the data space to progress through collaborative effort: by enabling you to take what others have already built, improve it, deploy it, and if possible, hand it back for someone else to do the same.
It's early days and we still have a long way to go, but the foundation is here and we’re seeing adoption ramp up quickly.
If you want to learn more or get involved, check out the open analytics taxonomy docs and the Objectiv repo on Github. You can also join the Objectiv slack channel if you have questions or ideas about it.
Office Hours
If you have any questions about this post or anything else, or if you just want to say 'Hi!' to team Objectiv, we have Office Hours every Thursday at 4pm CET, 10am EST that you can freely dial in to. If you're in a timezone that doesn’t fit well, just ping us on Slack and we'll send over an invite for a better moment.